Introduction
Lately I had to find a way to populate few office365 groups dynamically based on an enterprise application users & groups assignment to generate dynamic email lists. Long story short, we’re using the enterprise application as a provisioning tool to grant access to an external application. Check the documentation for more details. The plan was simple originally. We list the groups assigned to the enterprise app (I don’t have direct user assignment in this case), and then for each group, we list the members, to finally merge everything with a select -unique at the end. Of course, the plan has changed when I’ve discovered that for few enterprise applications I had more than 3000 groups assigned to it …
In this article, I will focus on how I’ve used batching with graph API to reduce the execution time from 14 min to 1 minute and 13 seconds.
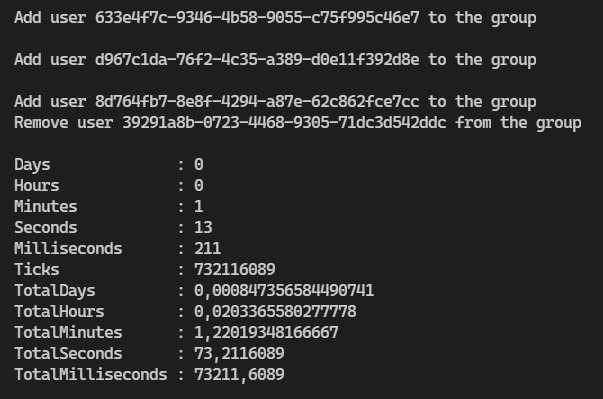
If you’re interested, you can find a demo code here.
Original plan
List the Enterprise app assignment
Here the most important line, /servicePrincipal is to query Enterprise applications where /application is for App registration.
"/servicePrincipals/<Enterprise app objectId>/appRoleAssignedTo?`$top=999&`$select=principalId"
This will give us the first 999 elements (groups in my case) assigned to this specific enterprise app. With more than 3k groups, we must deal with paging. I’m using the Get-AADAppRoleAssignedTo function as helper. You can find it in the loadme module.
List group membership
Now we have all groups, we just have to flat everything and add the result into an array. Here the main line again:
"/groups/<group principalId >/members?`$top=99"
If we have more than 99 members per group, we will have to manage paging again then store the result in a big array. This is the bad part, because we will have to call Graph API more than 3000 times in our case. The basic 3000 calls because of the number of groups and more if you have more than 99 users in some of them. In my case this part takes between 12 and 14 minutes. I’m using the Get-AADGroupMember function as helper available in the loadme module again.
Filter to remove duplicates
Now that we have an array full of duplicates, let’s simply clean it with:
$FinalResult = $BigQueryResults | Select-Object userPrincipalName,Id -Unique
Compare with the current group we want to sync
Nothing complicated here, I just use default Compare-Object cmdlet between the filtered object and the current members of the group we want to sync dynamically. Then I use the Add-AADGroupMember and Remove-AADGroupMember functions to update the group we want to sync.
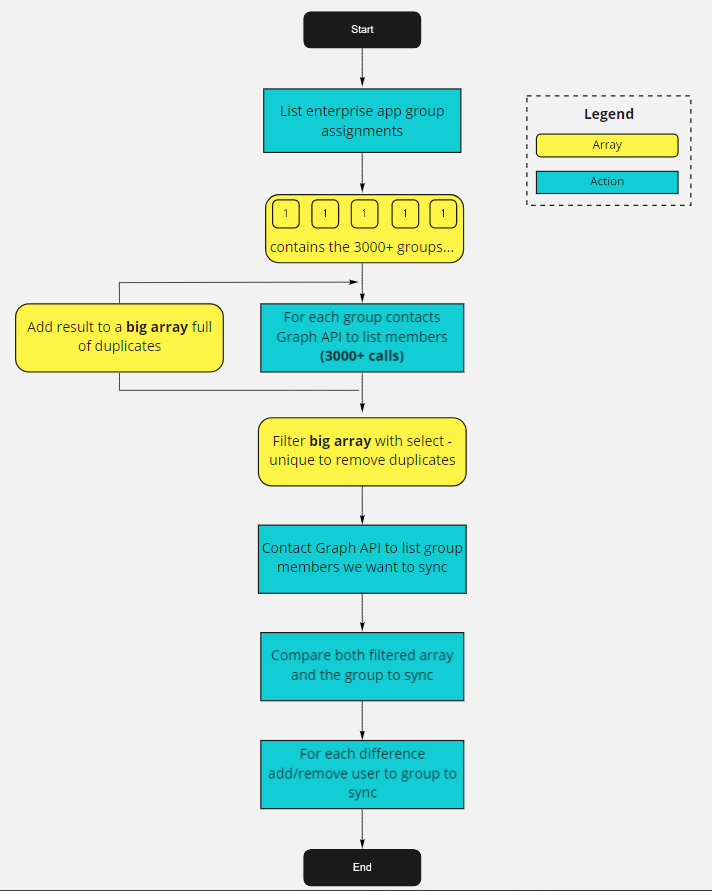
Visualization
If you’re more a visual person, the process look like this:
New plan
14 min, is not acceptable in my case. If I have 10 groups to populate, it can take a serious amount of time, so what can I do? My first thought was about parallel processing with runspaces but quickly I’ve decided to drop this idea to try the Graph API batch processing.
Long story short you format up to 20 requests in a single API call and graph API does the job for you. In other words, in our case we divide by 20 the number of direct graph requests.
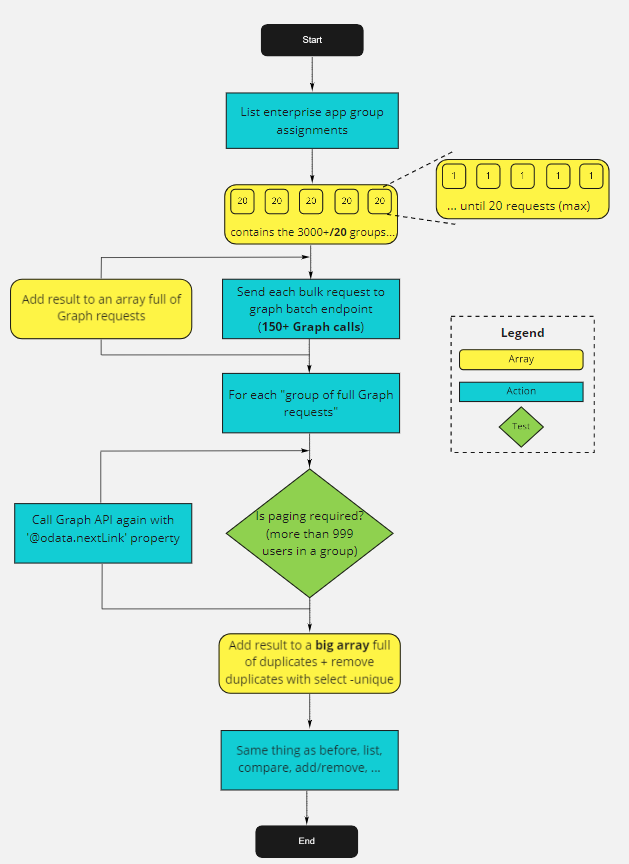
Here the big picture of the plan:
- Same as before, we list the group assignments to our enterprise app and grab our 3000+ groups.
- Now we split this variable in multiple 20 sized chunks (Thank you Internet for the Split-Array function). For each chunk we format the request in a specific format to be accepted by graph API batch endpoint and ask Graph to work for us.
- This is where it starts to be tricky. When you execute a Graph query from your machine, you do the Invoke-RestMethod (irm) and if the ‘@odata.nextLink’ property exists, you must manage paging. There is plenty of examples out there to take care of this problem with a loop. But, in our case, the first irm call is made by Graph itself (not you) in an “async” manner. So you have to do the second (or more) irm call(s) if you have to mange paging (more than 999 users per group). Therefore, you have to do something ugly like the code below where you have first to verify if the property ‘@odata.nextLink’ exists and take decision based on the answer.
Here an idea of the code:
foreach($response in $($bigBatchAnswer.responses)){
# Here we should have between 1 and 20 items
if($response.status -eq 200){
# From here we should have a bunch of users.
# IMPORTANT: This is the tricky part compared to when you fetch data from your machine. The first invoke-restmethod is made by the Graph batch endpoint and only if you need paging '@odata.nextLink' (more than 999 users in a group), in this case we will fetch locally, we won't ask batch again.
$QueryResults = @()
if($response.body.'@odata.nextLink'){
$Params = @{
Headers = $Headers
uri = $null
Body = $null
method = 'Get'
ErrorAction = 'Stop'
}
# Load first values and then go fetch the other data from paging
$QueryResults += $response.body.value | Select-Object Id,userPrincipalName
$Params.uri = $response.body.'@odata.nextlink'
do {
try{$Results = Invoke-RestMethod @Params}
catch{throw}
#Add new values
$QueryResults += $Results.value | Select-Object Id,userPrincipalName
$params.Uri = $Results.'@odata.nextLink'
} until (-not $Params.uri)
}
else{
# No paging here just take the value directly
$QueryResults += $response.body.value | Select-Object Id,userPrincipalName
}
# With or without nextlink, we don't care we just dump the result in the big collection
$QueryResults.ForEach({[void]$BigQueryResults.Add($_)})
}
else{
Write-Warning "Response other than 200 code: $response"
}
}
And that’s it 😊. For the rest, it’s like the long version where you compare the result between the current DL and the filtered array to then add/remove users accounts. The only difference is that now instead of 14 min, it takes less than 2 min.
Again if you prefer pictures, here a high level overview:
What about Azure AD?
Because we don’t want to be over privileged with application permission, we will have to create a service account that we will use to add/remove members with only delegated permission. To be able to run the GraphBatch.ps1 script, you will have to configure few things first:
- Create a new account in your AAD
- Make it owner of the group(s) you want to dynamically populate
- Create a new App registration and grant:
- Group.Read.All (Delegated) to allow us to read all directory groups and group members.
- Application.Read.All (Delegated) to allow us to read groups assignment to our app.
- GroupMember.ReadWrite.All (Delegated) to allow us to add/remove members to our DL(s) that we own.
- Enable Public application (We will use ROPC in our case because we don’t want user interraction)
- Create a desktop app redirect URI with the value http://localhost
Now we’re good to go and only the groups we own can be modified (not all tenant’s groups).
Conclusion
Nothing complicated in this article, Graph API batch seems to be a good fit when you have to do a massive number of queries. If you wonder why I decided to take this path, I will answer this question during the next article(s). But in short, I wanted to learn ACI (Azure Container Instance) and this dynamic group automation seems to be a good candidate. In addition, with ACI, it’s a per seconds billing, so a 2 min run will be cheaper than a 15 min run (no really???). See you for the next one.